About¶
Tutorial notebook¶
The following jupyter notebook online (in the browser) demonstrates the usage of pyradigm and its multiple classes, in a tutorial fashion. You don’t need any setup or software to use it.
Introduction¶
A common problem for machine learning developers is keeping track of the source of the features extracted during the full extent of data processing and pipelines, and to ensure integrity of the dataset i.e. not getting data mixed up from different subjects, labels or classes, regadless of whether it was accidental or inadvertent or otherwise. When the feature sets are maintained in a CSV file that does not retain any identifying information for the rows, keeping track of where the features come from is incredibly hard. This is hard even for tech savvy capable developers esp. as the number of projects grow, or personnel changes are frequent. Such aspects can break the chain of hyper-local info about various datasets, such as where did the original data come from, how was it processed or quality controlled, how was it assembled, by who and what does some columns in the table mean etc. This package aims to provide a Python-based container data structure to encapsulate a machine learning dataset with all the key info necessary. This is greatly suited for neuroscience and neuroimaging applications (and other similar domains), where each sample needs to be uniquely identified with an unique (like subject or session ID or something hashable). Such key-level correspondence across data/features, labels (e.g. 1 or 2), class names (e.g. ‘healthy’, ‘disease’) and the related attributes is crucial to ensure and maintain data integrity. Moreover, meta data fields and other attributes like free-text description help annotate all the important information. pyradigm class methods offer the ability to arbitrarily combine and subset datasets, while ensuring the dataset integrity and automatically updating their description and other provenance helps reduce the developer burden.
Check the Features and usage and API pages, and let me know your comments.
Schematic¶
A schematic illustrating the function of the pyradigm’s BaseDataset is shown below, wherein a single ClassificationDataset or RegressionDataset links and encapsulates the data table X with targets y and attributes A:
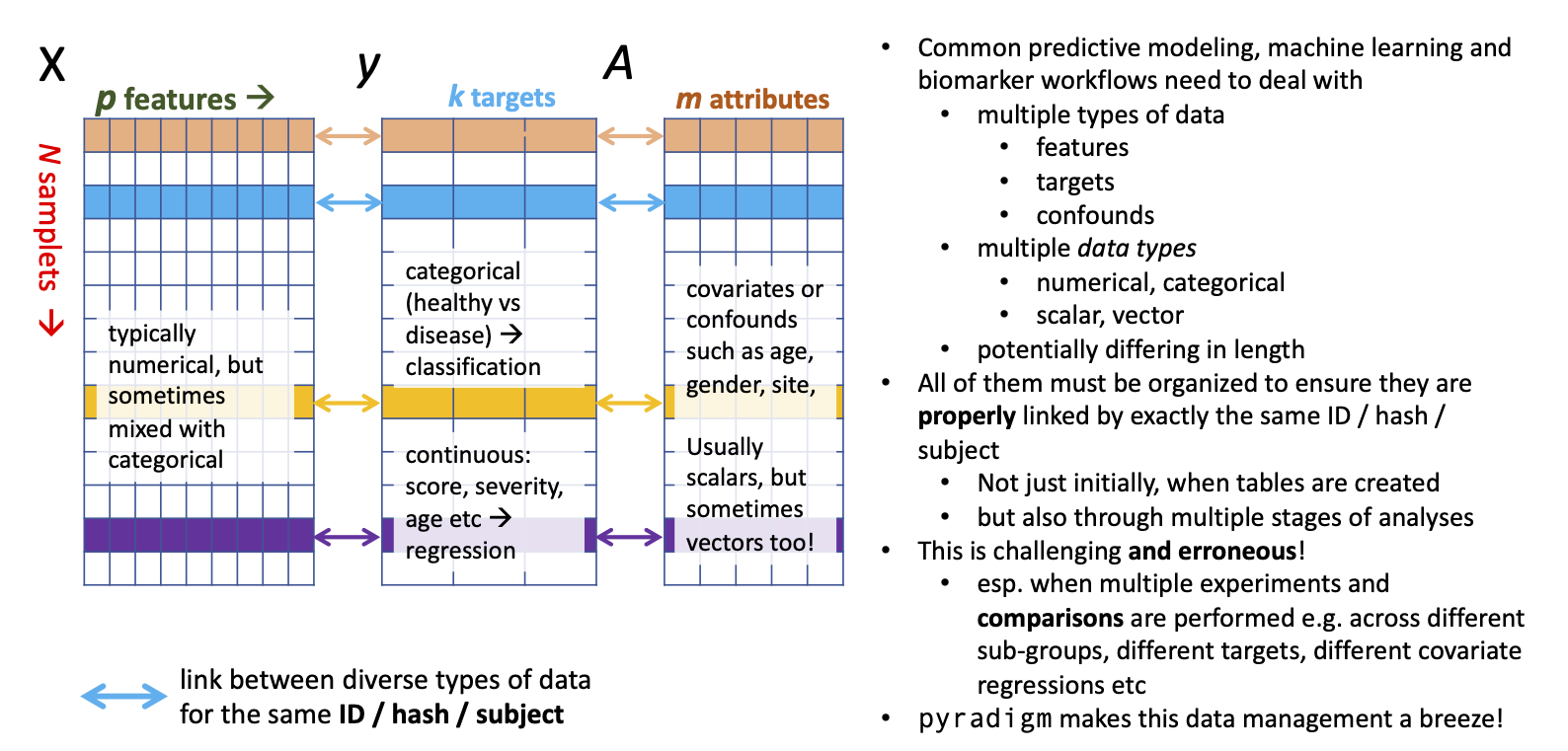
A related important class is a container data structure to hold and manage multiple datasets is MultiDataset.
Notes¶
Some of the elements in pyradigm’s API/interface may look familiar or similar to that of other containers like Pandas, Xarray and the like, owing to the similarity in nature of the operations. However, the aim of this pyradigm data structure is to simplify the interface as much as possible, reduce the cognitive burden for the user with domain-native language and intuitive operations etc, targeting machine learning workflows for nice domains neuroscientists and the like. This is achieved by
offering several well-knit methods and useful attributes specifically geared towards neuroscience research,
aiming to offer utilities that combines multiple or advanced patterns of routine dataset handling and
using a more accessible language (compared to hard to read pandas docs aimed at econometric audience) to better cater to neuroscience developers (esp. the novice).
Thanks for checking out pyradigm. Your feedback will be appreciated.